About
The Cornell Phonetics Lab is a group of students and faculty who are curious about speech. We study patterns in speech — in both movement and sound. We do a variety research — experiments, fieldwork, and corpus studies. We test theories and build models of the mechanisms that create patterns. Learn more about our Research. See below for information on our events and our facilities.

Upcoming Events

28th April 2022 04:30 PM
Linguistics Colloquium Talk by Dr. Adamantios Gafos of Potsdam University
The Department of Linguistics proudly presents Dr. Adamantios Gafos, Professor, Linguistics and Excellence Area of Cognitive Science, Senior Scientist at University of Potsdam.
This Colloquium Talk Series is sponsored by the Cornell Department of Linguistics & The Cornell Linguistics Circle.
Please contact Heather Russell at hlm2@cornell.edu for the Zoom link.
Location:
3rd May 2022 04:30 PM
"Speaking My Soul: Race, Life, and Language - A Reading"
Dr. John Rickford (Stanford University) is an A.D. White Professor-at-Large at Cornell, and will give a talk titled:
"Speaking My Soul: Race, Life, and Language - A Reading", which will be held at Hollis E. Cornell Auditorium (132 Goldwin Smith Hall) and via Zoom
About the speaker:
John Russell Rickford is a world-renowned linguist and award-winning author, whose autobiography, Speaking my Soul: Race, Life and Language, was released in December 2021. Speaking my Soul is the honest story of Rickford’s life from his early years as the youngest of ten children in Guyana to his status as Emeritus Professor of Linguistics at Stanford, of the transformation of his identity from colored or mixed race in Guyana to black in the USA, and of his work championing Black Talk and its speakers.
This is an inspiring story of the personal and professional growth of a black scholar, from his life as an immigrant to the USA to a world-renowned expert who has made a leading contribution to the study of African American life, history, language and culture. In this engaging memoir, Rickford recalls landmark events for his racial identity like being elected president of the Black Student Association at the University of California, Santa Cruz; learning from black expeditions to the South Carolina Sea Islands, Jamaica, Belize and Ghana; and meeting or interviewing civil rights icons like Huey P. Newton, Rosa Parks and South African Dennis Brutus. He worked with Rachel Jeantel, Trayvon Martin’s good friend, and key witness in the trial of George Zimmerman for his murder—Zimmerman’s exoneration sparked the Black Lives Matter movement.
Location: John Rickford, A. D. White Professor-at-Large: "Speaking my Soul: Race, Life and Language-A Reading"4th May 2022 12:20 PM
PhonDAWG - Phonetics Lab Data Analysis Working Group
Nielson will give a practice talk.
Location: B11, Morrill Hall
5th May 2022 04:30 PM
Linguistics Colloquium: “NOT hearing African American Vernacular English, as shown by errors in the Automated Speech Recognition Systems (ASRs) used by Amazon, Apple, Microsoft, Google, IBM"
The Department of Linguistics proudly presents John Rickford, A.D. White Professor-at-Large at Cornell, and Professor of Linguistics emeritus and the J.E. Wallace Sterling Professor of the Humanities, Professor of Education (by courtesy), and a Bass University Fellow in Undergraduate Education at Stanford University.
Dr. Rickford will speak on "NOT hearing African American Vernacular English, as shown by errors in the Automated Speech Recognition Systems (ASRs) used by Amazon, Apple, Microsoft, Google, IBM".
Abstract:
African American Vernacular English (AAVE) is by far the most studied variety of American English, yet most non-linguists either ignore or deny it, or notice it only when it is the source of national controversies in education, as it was in the 1996 Oakland Ebonics firestorm.
Recently, however, it became an issue of concern when Koenecke et al (2020) showed that the Automated Speech Recognition (ASR) systems used by Amazon, Apple, Google, IBM and Microsoft had on average twice as many errors when transcribing the speech of black speakers as they did when transcribing the speech of white speakers.
In this talk I’ll discuss what AAVE is and explain some of the challenges its pronunciation and grammar represent for the ASRs of Apple and other systems.
From there we will proceed to examples of actual speech snippets used to test the ASRs of Apple and other systems, illustrating some of the specific difficulties they caused. We will also introduce limited evidence of difficulties that ASRs faced with Latino English and discuss possible solutions to these recurrent limitations with ASR devices.
References:
Koenecke, A. Nam, E. Lake, J. Nudell, M. Quartey, Z. Mengesha, C. Toups, J. R. Rickford, D Jurafsky, and S Goel. Racial disparities in automated speech recognition. PNAS (Proceedings of the National Academy of Science) Oct 5, 2019. 10.1073/pnas.1915768117
About our Speaker:
John Rickford is a leading sociolinguist and world-renowned expert on African American Vernacular English (AAVE) and the study of linguistic variation and change.
Professor Rickford is considered one of the towering figures in the linguistic and historical study of vernacular language in the African diaspora. He is one of the small number of scholars in the field–Noam Chomsky and William Labov—to deserve the title of leading research linguist and prominent public intellectual. His scholarly contributions run the gamut from important descriptive research on African-American Vernacular English (AAVE) and Caribbean varieties, to work of historical significance on the origins of AAVE, to research on AAVE syntactic patterns with important consequences for syntactic theory, to his current research demonstrating that basic linguistic misconceptions may influence major legal and political decisions, and that the automatic speech recognition systems used by Apple, Microsoft and other companies make considerably more errors with Black and Latin-X speakers than with White ones.
Since the 1970s he had worked to document AAVE and other varieties of English spoken throughout North America and the Caribbean, which has contributed significantly to the understanding of the grammatical regularities and structure of AAVE. He was a strong voice of reason during the national Ebonics debate when the Oakland School Board decided to recognize the vernacular of their African American students and use it in the teaching of Standard English.
His recent work bridges the disciplines of social linguistics with legal studies, analyzing the adverse consequences of the misunderstanding of African American Vernacular English (AAVE) in criminal trials. Modern linguistics teaches that all varieties of human language are qualitatively equivalent, but this result does not stem from political correctness; it is the result of a century of linguistic research, including the work of Labov and Rickford and their colleagues over the past five decades on nonstandard North American Englishes. The basic inability to distinguish between linguistic difference and quality of thought or expression leads to tragic results in our courts and public discourse—this is best recognized most recently through his work relating to testimonies in the well-publicized Travon Martin murder investigation.
Among his numerous honors, Professor Rickford was the President of the Linguistic Society of America (LSA) from 2015-2016, from which he was recently awarded the best paper in Language 2016 Award. He is a member of the American Academy of Arts and Sciences (since 2017), and he was recently elected to the National Academy of Sciences (2021).
ASL interpretation will be available for this talk.
Location: "NOT hearing African American Vernacular English, as shown by errors in the Automated Speech Recognition Systems (ASRs) used by Amazon, Apple, Microsoft, Google, IBM".
Facilities
The Cornell Phonetics Laboratory (CPL) provides an integrated environment for the experimental study of speech and language, including its production, perception, and acquisition.
Located in Morrill Hall, the laboratory consists of six adjacent rooms and covers about 1,600 square feet. Its facilities include a variety of hardware and software for analyzing and editing speech, for running experiments, for synthesizing speech, and for developing and testing phonetic, phonological, and psycholinguistic models.
Web-Based Phonetics and Phonology Experiments with LabVanced
The Phonetics Lab licenses the LabVanced software for designing and conducting web-based experiments.
Labvanced has particular value for phonetics and phonology experiments because of its:
- *Flexible audio/video recording capabilities and online eye-tracking.
- *Presentation of any kind of stimuli, including audio and video
- *Highly accurate response time measurement
- *Researchers can interactively build experiments with LabVanced's graphical task builder, without having to write any code.
Students and Faculty are currently using LabVanced to design web experiments involving eye-tracking, audio recording, and perception studies.
Subjects are recruited via several online systems:
- * Prolific and Amazon Mechanical Turk - subjects for web-based experiments.
- * Sona Systems - Cornell subjects for for LabVanced experiments conducted in the Phonetics Lab's Sound Booth

Computing Resources
The Phonetics Lab maintains two Linux servers that are located in the Rhodes Hall server farm:
- Lingual - This Ubuntu Linux web server hosts the Phonetics Lab Drupal websites, along with a number of event and faculty/grad student HTML/CSS websites.
- Uvular - This Ubuntu Linux dual-processor, 24-core, two GPU server is the computational workhorse for the Phonetics lab, and is primarily used for deep-learning projects.
In addition to the Phonetics Lab servers, students can request access to additional computing resources of the Computational Linguistics lab:
- *Badjak - a Linux GPU-based compute server with eight NVIDIA GeForce RTX 2080Ti GPUs
- *Compute server #2 - a Linux GPU-based compute server with eight NVIDIA A5000 GPUs
- *Oelek - a Linux NFS storage server that supports Badjak.
These servers, in turn, are nodes in the G2 Computing Cluster, which currently consists of 195 servers (82 CPU-only servers and 113 GPU servers) consisting of ~7400 CPU cores and 698 GPUs.
The G2 Cluster uses the SLURM Workload Manager for submitting batch jobs that can run on any available server or GPU on any cluster node.
Articulate Instruments - Micro Speech Research Ultrasound System
We use this Articulate Instruments Micro Speech Research Ultrasound System to investigate how fine-grained variation in speech articulation connects to phonological structure.
The ultrasound system is portable and non-invasive, making it ideal for collecting articulatory data in the field.

BIOPAC MP-160 System
The Sound Booth Laboratory has a BIOPAC MP-160 system for physiological data collection. This system supports two BIOPAC Respiratory Effort Transducers and their associated interface modules.

Language Corpora
- The Cornell Linguistics Department has more than 915 language corpora from the Linguistic Data Consortium (LDC), consisting of high-quality text, audio, and video corpora in more than 60 languages. In addition, we receive three to four new language corpora per month under an LDC license maintained by the Cornell Library.
- This Linguistic Department web page lists all our holdings, as well as our licensed non-LDC corpora.
- These and other corpora are available to Cornell students, staff, faculty, post-docs, and visiting scholars for research in the broad area of "natural language processing", which of course includes all ongoing Phonetics Lab research activities.
- This Confluence wiki page - only available to Cornell faculty & students - outlines the corpora access procedures for faculty supervised research.

Speech Aerodynamics
Studies of the aerodynamics of speech production are conducted with our Glottal Enterprises oral and nasal airflow and pressure transducers.

Electroglottography
We use a Glottal Enterprises EG-2 electroglottograph for noninvasive measurement of vocal fold vibration.

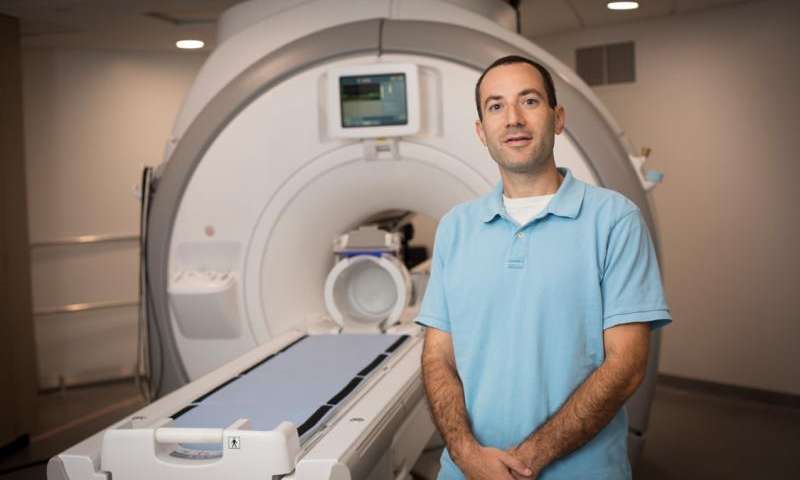
Real-time vocal tract MRI
Our lab is part of the Cornell Speech Imaging Group (SIG), a cross-disciplinary team of researchers using real-time magnetic resonance imaging to study the dynamics of speech articulation.
Articulatory movement tracking
We use the Northern Digital Inc. Wave motion-capture system to study speech articulatory patterns and motor control.

Sound Booth
Our isolated sound recording booth serves a range of purposes--from basic recording to perceptual, psycholinguistic, and ultrasonic experimentation.
We also have the necessary software and audio interfaces to perform low latency real-time auditory feedback experiments via MATLAB and Audapter.

©Copyright 2020, Cornell University