About
The Cornell Phonetics Lab is a group of students and faculty who are curious about speech. We study patterns in speech — in both movement and sound. We do a variety research — experiments, fieldwork, and corpus studies. We test theories and build models of the mechanisms that create patterns. Learn more about our Research. See below for information on our events and our facilities.

Upcoming Events
4th November 2022 12:20 PM
Phonetics Lab Meeting
We will discuss this reading on unsupervised phonological feature learning, available here.
Location: B11, Morrill Hall
4th November 2022 06:00 PM
The ASL Literature Series: The Flying Words Project performs at Kennedy Hall
The Cornell Linguistic Department's ASL/Deaf Studies Program is proud to sponsor a performance by The Flying Words Project at Call Auditorium, Kennedy Hall on Friday, Nov 4 6-7:30PM.
Flying Words consists of Peter Cook and Kenny Lerner. Peter is the chairperson for the Deaf Studies/ASL-English Interpretation program at Columbia College in Chicago, IL. Kenny Lerner is a senior lecturer of history at the Rochester Institute of Technology/National Technical Institute for the deaf in Rochester, NY
Their performance is part of the Fall 2022 ASL Literature Series.
Abstract:
The work of Peter Cook and Kenny Lerner is a beautiful and fascinating combination of American Sign Language (ASL), movement, visual theater, and above all, extraordinary poetry.
Deaf American Sign Language poet Peter Cook presents three dimensional imagery while collaborator Kenny Lerner’s spoken words allow the hearing portion of the audience to literally see the ASL image and become lost in the movement. Together they create a moving tapestry uniquely accessible to both deaf and hearing audiences.
Two of the pioneers of ASL poetry, they have been at the center of this radical cultural movement since it’s modern inception in the early 1980s. Performing all over the world for over 30 years, they have helped to establish not only an artistic form (Deaf Poetry in ASL) but also have contributed a new vision of poetry itself.
This collaboration commenced in 1984 when Cook and Lerner began performing poetry together. They soon established the only deaf poetry series in the U.S. at that time which culminated in the First National ASL Literature Conference in 1992. Flying Words has been featured at the Poetry Days Festival (Dzejas Dienas,) in the Latvian towns of Liepia and Riga. They have also performed at the 36th International Poetry Festival in Rotterdam, the Netherlands, Kent State University, the Walker Art Center in Minneapolis, Harvard University, and last summer (2022) in the Annikki Poetry Festival, Tampere, Finland. In addition, in 2019, Flying Words was proud to present the keynote address at the American Literary Translators Association Conference in Rochester, NY.
Flying Words has been the recipients of grants from the New York State Council of the Arts, the National Endowment for the Arts, and the Puffin Foundation and are the authors of four DVD anthologies.
Location: Kennedy Hall, Call Auditorium9th November 2022 12:20 PM
PhonDAWG - Phonetics Lab Data Analysis Working Group
Today we'll read Binna's conference abstract and provide feedback. Zoom will be live.
Location: B11, Morrill Hall
10th November 2022 04:30 PM
Linguistics Colloquium Speaker: Josef Fruehwald
The Department of Linguistics proudly presents Dr. Josef Fruehwald, Assistant Professor of Linguistics at the University of Kentucky.
Dr. Fruehwald will speak on "Sound Change? Incrementation? Diffusion?".
Talk Abstract:
Many subfields of linguistics have an interest in "Sound Change" either as a topic in and of itself or as phenomenon to explore other phonetic, phonological, cognitive, or social questions.
While we do have a common vocabulary ("sound change", "actuation", "incrementation", "diffusion") and a common set of phenomena ("s-shaped curves"), these commonalities can obscure underlyingly incommensurate conceptualizations of *how* sound change happens.
One model, more common from phonetics or laboratory phonology, I'll call the "Uptake Model", whereby sound change spreads much like the uptake of other social or technological innovations, with "early adopters" and the gradual accumulation of new "users."
Another model, more common from sociolinguistics and sociophonetics, I'll call the Participation Model, whereby all members of a language community *participate* in a change. The Uptake Model, or versions of it, appears to be more commonly presupposed, and often form the underpinning of agent-based simulations of language change.
However, I'll argue, on the basis of quantitative analysis of a large diachronic speech corpus (the Philadelphia Neighborhood Corpus) that the Participation Model seems better supported by naturalistic data.
Bio:
Dr. Fruehwald is an Assistant Professor in the Linguistics Department at the University of Kentucky. His interests within linguistics are sociolinguistics, variation and change, phonetics, and phonology.
Location: Morrill Hall, Room 106
Facilities
The Cornell Phonetics Laboratory (CPL) provides an integrated environment for the experimental study of speech and language, including its production, perception, and acquisition.
Located in Morrill Hall, the laboratory consists of six adjacent rooms and covers about 1,600 square feet. Its facilities include a variety of hardware and software for analyzing and editing speech, for running experiments, for synthesizing speech, and for developing and testing phonetic, phonological, and psycholinguistic models.
Web-Based Phonetics and Phonology Experiments with LabVanced
The Phonetics Lab licenses the LabVanced software for designing and conducting web-based experiments.
Labvanced has particular value for phonetics and phonology experiments because of its:
- *Flexible audio/video recording capabilities and online eye-tracking.
- *Presentation of any kind of stimuli, including audio and video
- *Highly accurate response time measurement
- *Researchers can interactively build experiments with LabVanced's graphical task builder, without having to write any code.
Students and Faculty are currently using LabVanced to design web experiments involving eye-tracking, audio recording, and perception studies.
Subjects are recruited via several online systems:
- * Prolific and Amazon Mechanical Turk - subjects for web-based experiments.
- * Sona Systems - Cornell subjects for for LabVanced experiments conducted in the Phonetics Lab's Sound Booth

Computing Resources
The Phonetics Lab maintains two Linux servers that are located in the Rhodes Hall server farm:
- Lingual - This Ubuntu Linux web server hosts the Phonetics Lab Drupal websites, along with a number of event and faculty/grad student HTML/CSS websites.
- Uvular - This Ubuntu Linux dual-processor, 24-core, two GPU server is the computational workhorse for the Phonetics lab, and is primarily used for deep-learning projects.
In addition to the Phonetics Lab servers, students can request access to additional computing resources of the Computational Linguistics lab:
- *Badjak - a Linux GPU-based compute server with eight NVIDIA GeForce RTX 2080Ti GPUs
- *Compute server #2 - a Linux GPU-based compute server with eight NVIDIA A5000 GPUs
- *Oelek - a Linux NFS storage server that supports Badjak.
These servers, in turn, are nodes in the G2 Computing Cluster, which currently consists of 195 servers (82 CPU-only servers and 113 GPU servers) consisting of ~7400 CPU cores and 698 GPUs.
The G2 Cluster uses the SLURM Workload Manager for submitting batch jobs that can run on any available server or GPU on any cluster node.
Articulate Instruments - Micro Speech Research Ultrasound System
We use this Articulate Instruments Micro Speech Research Ultrasound System to investigate how fine-grained variation in speech articulation connects to phonological structure.
The ultrasound system is portable and non-invasive, making it ideal for collecting articulatory data in the field.

BIOPAC MP-160 System
The Sound Booth Laboratory has a BIOPAC MP-160 system for physiological data collection. This system supports two BIOPAC Respiratory Effort Transducers and their associated interface modules.

Language Corpora
- The Cornell Linguistics Department has more than 915 language corpora from the Linguistic Data Consortium (LDC), consisting of high-quality text, audio, and video corpora in more than 60 languages. In addition, we receive three to four new language corpora per month under an LDC license maintained by the Cornell Library.
- This Linguistic Department web page lists all our holdings, as well as our licensed non-LDC corpora.
- These and other corpora are available to Cornell students, staff, faculty, post-docs, and visiting scholars for research in the broad area of "natural language processing", which of course includes all ongoing Phonetics Lab research activities.
- This Confluence wiki page - only available to Cornell faculty & students - outlines the corpora access procedures for faculty supervised research.

Speech Aerodynamics
Studies of the aerodynamics of speech production are conducted with our Glottal Enterprises oral and nasal airflow and pressure transducers.

Electroglottography
We use a Glottal Enterprises EG-2 electroglottograph for noninvasive measurement of vocal fold vibration.

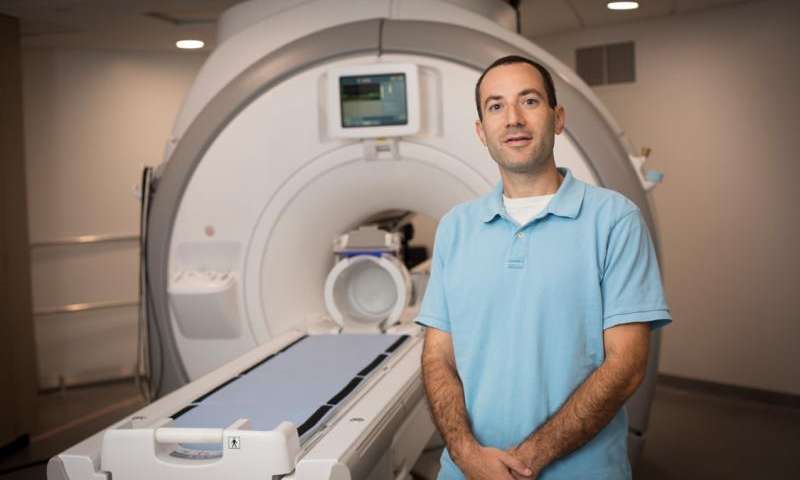
Real-time vocal tract MRI
Our lab is part of the Cornell Speech Imaging Group (SIG), a cross-disciplinary team of researchers using real-time magnetic resonance imaging to study the dynamics of speech articulation.
Articulatory movement tracking
We use the Northern Digital Inc. Wave motion-capture system to study speech articulatory patterns and motor control.

Sound Booth
Our isolated sound recording booth serves a range of purposes--from basic recording to perceptual, psycholinguistic, and ultrasonic experimentation.
We also have the necessary software and audio interfaces to perform low latency real-time auditory feedback experiments via MATLAB and Audapter.

©Copyright 2020, Cornell University