About
The Cornell Phonetics Lab is a group of students and faculty who are curious about speech. We study patterns in speech — in both movement and sound. We do a variety research — experiments, fieldwork, and corpus studies. We test theories and build models of the mechanisms that create patterns. Learn more about our Research. See below for information on our events and our facilities.

Upcoming Events

19th November 2020 04:10 PM
CLC Speaker Series: Rebecca Morley from Ohio State University
The Cornell Linguistics Circle proudly presents Professor Rebecca Morley from the Ohio State University.
Location: CLC Speaker Series: Rebecca Morley
30th November 2020 11:30 AM
Automatic Movie Analysis and Summarization via Turning Point Identification
Movie analysis is an umbrella term for many tasks aiming to automatically interpret, extract, and summarize the content of a movie. Potential applications include generating shorter versions of scripts to help with the decision making process in a production company, enhancing movie recommendation engines, and notably generating movie previews.
In this talk I will introduce the task of turning point identification as a means of analyzing movie content. According to screenwriting theory, turning points (e.g., change of plans, major setback, climax) are crucial narrative moments within a movie: they define its plot structure, determine its progression and segment it into thematic units. I will argue that turning points and the segmentation they provide can facilitate the analysis of long, complex narratives, such as screenplays. I will further formalize the generation of a shorter version of a movie as the problem of identifying scenes with turning points and present a graph neural network model for this task based on linguistic and audiovisual information. Finally, I will discuss why the representation of screenplays as (sparse) graphs offers interpretability and exposes the morphology of different movie genres.
Bio: Mirella Lapata is professor of natural language processing in the School of Informatics at the University of Edinburgh. Her research focuses on getting computers to understand, reason with, and generate natural language. She is the first recipient (2009) of the BCS and Information Retrieval Specialist Group (BCS/IRSG) Karen Sparck ones award and a Fellow of the Royal Society of Edinburgh. She has also received best paper awards in leading NLP conferences and has served on the editorial boards of the Journal of Artificial Intelligence Research, the Transactions of the ACL, and Computational Linguistics. She was president of SIGDAT (the group that organises EMNLP) in 2018.
Location: Colloquium Link
3rd December 2020 02:00 PM
Creating an Effective CV (Curriculum Vitae) - lecture by Dr. Jean-luc Doumont
Please join us on Thu 3 Dec at 20:00 CET (2PM Eastern Standard Time) for ‘Creating an effective curriculum vitae’, a classic communication lecture by Dr Jean-luc Doumont for students and professionals at any stage in their careers.
As always for our open lectures, anyone is welcome to attend, free of charge—within the capacity of the (virtual) auditorium—but must register first and get a personal Zoom link to attend.
Comment by Cornell's Dr. Sam Tilsen:
"Jean-luc Doumont also has a lecture on designing Academic powerpoint presentations which we have watched in the past, and I recommend that all grad students watch at some point."
Location: Registration
Facilities
The Cornell Phonetics Laboratory (CPL) provides an integrated environment for the experimental study of speech and language, including its production, perception, and acquisition.
Located in Morrill Hall, the laboratory consists of six adjacent rooms and covers about 1,600 square feet. Its facilities include a variety of hardware and software for analyzing and editing speech, for running experiments, for synthesizing speech, and for developing and testing phonetic, phonological, and psycholinguistic models.
Web-Based Phonetics and Phonology Experiments with LabVanced
The Phonetics Lab licenses the LabVanced software for designing and conducting web-based experiments.
Labvanced has particular value for phonetics and phonology experiments because of its:
- *Flexible audio/video recording capabilities and online eye-tracking.
- *Presentation of any kind of stimuli, including audio and video
- *Highly accurate response time measurement
- *Researchers can interactively build experiments with LabVanced's graphical task builder, without having to write any code.
Students and Faculty are currently using LabVanced to design web experiments involving eye-tracking, audio recording, and perception studies.
Subjects are recruited via several online systems:
- * Prolific and Amazon Mechanical Turk - subjects for web-based experiments.
- * Sona Systems - Cornell subjects for for LabVanced experiments conducted in the Phonetics Lab's Sound Booth

Computing Resources
The Phonetics Lab maintains two Linux servers that are located in the Rhodes Hall server farm:
- Lingual - This Ubuntu Linux web server hosts the Phonetics Lab Drupal websites, along with a number of event and faculty/grad student HTML/CSS websites.
- Uvular - This Ubuntu Linux dual-processor, 24-core, two GPU server is the computational workhorse for the Phonetics lab, and is primarily used for deep-learning projects.
In addition to the Phonetics Lab servers, students can request access to additional computing resources of the Computational Linguistics lab:
- *Badjak - a Linux GPU-based compute server with eight NVIDIA GeForce RTX 2080Ti GPUs
- *Compute server #2 - a Linux GPU-based compute server with eight NVIDIA A5000 GPUs
- *Oelek - a Linux NFS storage server that supports Badjak.
These servers, in turn, are nodes in the G2 Computing Cluster, which currently consists of 195 servers (82 CPU-only servers and 113 GPU servers) consisting of ~7400 CPU cores and 698 GPUs.
The G2 Cluster uses the SLURM Workload Manager for submitting batch jobs that can run on any available server or GPU on any cluster node.
Articulate Instruments - Micro Speech Research Ultrasound System
We use this Articulate Instruments Micro Speech Research Ultrasound System to investigate how fine-grained variation in speech articulation connects to phonological structure.
The ultrasound system is portable and non-invasive, making it ideal for collecting articulatory data in the field.

BIOPAC MP-160 System
The Sound Booth Laboratory has a BIOPAC MP-160 system for physiological data collection. This system supports two BIOPAC Respiratory Effort Transducers and their associated interface modules.

Language Corpora
- The Cornell Linguistics Department has more than 915 language corpora from the Linguistic Data Consortium (LDC), consisting of high-quality text, audio, and video corpora in more than 60 languages. In addition, we receive three to four new language corpora per month under an LDC license maintained by the Cornell Library.
- This Linguistic Department web page lists all our holdings, as well as our licensed non-LDC corpora.
- These and other corpora are available to Cornell students, staff, faculty, post-docs, and visiting scholars for research in the broad area of "natural language processing", which of course includes all ongoing Phonetics Lab research activities.
- This Confluence wiki page - only available to Cornell faculty & students - outlines the corpora access procedures for faculty supervised research.

Speech Aerodynamics
Studies of the aerodynamics of speech production are conducted with our Glottal Enterprises oral and nasal airflow and pressure transducers.

Electroglottography
We use a Glottal Enterprises EG-2 electroglottograph for noninvasive measurement of vocal fold vibration.

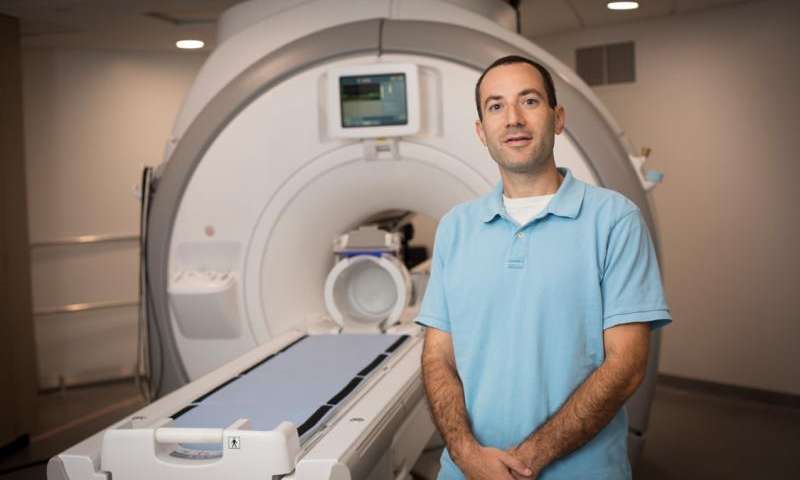
Real-time vocal tract MRI
Our lab is part of the Cornell Speech Imaging Group (SIG), a cross-disciplinary team of researchers using real-time magnetic resonance imaging to study the dynamics of speech articulation.
Articulatory movement tracking
We use the Northern Digital Inc. Wave motion-capture system to study speech articulatory patterns and motor control.

Sound Booth
Our isolated sound recording booth serves a range of purposes--from basic recording to perceptual, psycholinguistic, and ultrasonic experimentation.
We also have the necessary software and audio interfaces to perform low latency real-time auditory feedback experiments via MATLAB and Audapter.

©Copyright 2020, Cornell University