About
The Cornell Phonetics Lab is a group of students and faculty who are curious about speech. We study patterns in speech — in both movement and sound. We do a variety research — experiments, fieldwork, and corpus studies. We test theories and build models of the mechanisms that create patterns. Learn more about our Research. See below for information on our events and our facilities.

Upcoming Events

6th September 2023 12:20 PM
PhonDAWG - Phonetics Lab Data Analysis Working Group
Jeremy and Sam will get feedback on phonologically ambiguous orthographic stimuli they are preparing for an online norming study.
Location: B11 Morrill Hall, 159 Central Avenue, Morrill Hall, Ithaca, NY 14853-4701, USA
7th September 2023 04:30 PM
Colloquium Talk by Vera Gribanova
The Linguistics Colloquium Talk series proudly presents a talk by Dr. Vera Gribanova, Associate Professor of Linguistics, Stanford University. Dr. Gribanova will give a talk titled:
The identity relation in ellipsis: variation in its domain of application
This talk is funded in part by the GPSAFC and open to the graduate community.
Abstract:
Discussions of the identity relation in constituent ellipsis licensing often take for granted, either explicitly or implicitly, the idea that the identity relation in ellipsis ought to be uniform, and applicable across different ellipsis configurations and languages. Recent investigations of this relation — Rudin 2019, Anand et al. 2021, To appear, Stigliano 2022 — have provided novel evidence and arguments in support of the view that the domain of application of the identity relation is not always coextensive with the elided constituent itself.For example, although the prevailing view of English sluicing as TP ellipsis historically took the domain of the identity relation to likewise be the TP (Merchant, 2001), one of the main findings of the UCSC sluicing dataset is that material above the level of vP — e.g. tense/finiteness, modality, and polarity — can undergo felicitous mismatches. Generalizing beyond English sluicing, this raises the question of whether the domain of ellipsis identity must always be a proper subset of the domain of ellipsis itself, or if the specific size of the domain relevant for the identity relation may be variable across languages and ellipsis configurations.
In this talk, I present an investigation of some asymmetries in how case connectivity is enforced in two types of Russian clausal (TP) ellipsis — contrastive polarity ellipsis and fragment ellipsis — and develop an analysis explaining why these asymmetries take the shape that they do. The case study leverages the availabil- ity of a well-known case alternation between structural (nominative/accusative) case and genitive case under negation.The first asymmetry is that case connectivity on remnants of these two ellipsis types is enforced fully only in fragment ellipsis, but not in contrastive polarity ellipsis, in which a contrastive DP is fronted to the left periphery, preceding a polar particle (‘yes’ or ‘no’).
The second asymmetry is that in contrastive polarity ellipsis, genitive patients under negation in the antecedent can correspond to an accusative patient remnant outside the ellipsis site, but not the reverse. To capture these asymmetries, I develop an analysis of the system of licensing relations that connects the syntax of polarity expression, negative concord, and genitive of negation, and combine this with a formulation of the identity relation in ellipsis in which head-to-head identity between the elided material and the antecedent must be invoked (Saab, 2008, 2010, 2022; Tanaka, 2011; Rudin, 2019; Stigliano, 2022).
For the asymmetries between these two types of Russian TP ellipsis to emerge within an internally con- sistent system of analytical commitments, it is critical that the domain of evaluation for identity in Russian TP ellipsis to be larger than in English sluicing, and likely coextensive with the elided TP.These findings support a view in which the domain of evaluation for the identity relation in (TP) ellipsis may vary across languages and ellipsis types. I argue that this overall picture is not consistent with an alternative interpretation of the facts, in which the domain of identity is always coextensive with the elided constituent, but subject to a looser isomorphism restriction which might still permit certain mismatches (Murphy, 2016; Ranero, 2021).
Finally, I point to an implementation of ellipsis licensing that can straightforwardly capture variation in the size of the domain relevant to ellipsis identity. This implementation arises directly from unifying existing analyses (Aelbrecht, 2010; Stigliano, 2022) in which certain sub-parts of the ellipsis function — non-pronunciation, syntactic licensing, and the identity relation — can be either grouped together, or broken up across several distinct heads in the clausal spine.
Bio:
Dr. Gribanova is a syntactician and a morphologist, with occasional forays into phonology. Her work focuses on phenomena whose analysis requires reference to all of these modules, and often involves detailed investigation of their interaction.
She got her start as a linguist focusing primarily on Russian and Slavic languages; since 2009, she has also been working on the under-described Turkic languages of Central Asia (primarily Uzbek).
Location: 106 Morrill Hall, 159 Central Avenue, Morrill Hall, Ithaca, NY 14853-4701, USA
8th September 2023 12:20 PM
Phonetics Lab Meeting
We will continue our planning for conferences and discuss journals to read.
Location: B11 Morrill Hall, 159 Central Avenue, Morrill Hall, Ithaca, NY 14853-4701, USA
13th September 2023 12:20 PM
PhonDAWG - Phonetics Lab Data Analysis Working Group
Chloe will describe her work on forced alignment of her experimental data.
Location: B11 Morrill Hall, 159 Central Avenue, Morrill Hall, Ithaca, NY 14853-4701, USA
Facilities
The Cornell Phonetics Laboratory (CPL) provides an integrated environment for the experimental study of speech and language, including its production, perception, and acquisition.
Located in Morrill Hall, the laboratory consists of six adjacent rooms and covers about 1,600 square feet. Its facilities include a variety of hardware and software for analyzing and editing speech, for running experiments, for synthesizing speech, and for developing and testing phonetic, phonological, and psycholinguistic models.
Web-Based Phonetics and Phonology Experiments with LabVanced
The Phonetics Lab licenses the LabVanced software for designing and conducting web-based experiments.
Labvanced has particular value for phonetics and phonology experiments because of its:
- *Flexible audio/video recording capabilities and online eye-tracking.
- *Presentation of any kind of stimuli, including audio and video
- *Highly accurate response time measurement
- *Researchers can interactively build experiments with LabVanced's graphical task builder, without having to write any code.
Students and Faculty are currently using LabVanced to design web experiments involving eye-tracking, audio recording, and perception studies.
Subjects are recruited via several online systems:
- * Prolific and Amazon Mechanical Turk - subjects for web-based experiments.
- * Sona Systems - Cornell subjects for for LabVanced experiments conducted in the Phonetics Lab's Sound Booth

Computing Resources
The Phonetics Lab maintains two Linux servers that are located in the Rhodes Hall server farm:
- Lingual - This Ubuntu Linux web server hosts the Phonetics Lab Drupal websites, along with a number of event and faculty/grad student HTML/CSS websites.
- Uvular - This Ubuntu Linux dual-processor, 24-core, two GPU server is the computational workhorse for the Phonetics lab, and is primarily used for deep-learning projects.
In addition to the Phonetics Lab servers, students can request access to additional computing resources of the Computational Linguistics lab:
- *Badjak - a Linux GPU-based compute server with eight NVIDIA GeForce RTX 2080Ti GPUs
- *Compute server #2 - a Linux GPU-based compute server with eight NVIDIA A5000 GPUs
- *Oelek - a Linux NFS storage server that supports Badjak.
These servers, in turn, are nodes in the G2 Computing Cluster, which currently consists of 195 servers (82 CPU-only servers and 113 GPU servers) consisting of ~7400 CPU cores and 698 GPUs.
The G2 Cluster uses the SLURM Workload Manager for submitting batch jobs that can run on any available server or GPU on any cluster node.
Articulate Instruments - Micro Speech Research Ultrasound System
We use this Articulate Instruments Micro Speech Research Ultrasound System to investigate how fine-grained variation in speech articulation connects to phonological structure.
The ultrasound system is portable and non-invasive, making it ideal for collecting articulatory data in the field.

BIOPAC MP-160 System
The Sound Booth Laboratory has a BIOPAC MP-160 system for physiological data collection. This system supports two BIOPAC Respiratory Effort Transducers and their associated interface modules.

Language Corpora
- The Cornell Linguistics Department has more than 915 language corpora from the Linguistic Data Consortium (LDC), consisting of high-quality text, audio, and video corpora in more than 60 languages. In addition, we receive three to four new language corpora per month under an LDC license maintained by the Cornell Library.
- This Linguistic Department web page lists all our holdings, as well as our licensed non-LDC corpora.
- These and other corpora are available to Cornell students, staff, faculty, post-docs, and visiting scholars for research in the broad area of "natural language processing", which of course includes all ongoing Phonetics Lab research activities.
- This Confluence wiki page - only available to Cornell faculty & students - outlines the corpora access procedures for faculty supervised research.

Speech Aerodynamics
Studies of the aerodynamics of speech production are conducted with our Glottal Enterprises oral and nasal airflow and pressure transducers.

Electroglottography
We use a Glottal Enterprises EG-2 electroglottograph for noninvasive measurement of vocal fold vibration.

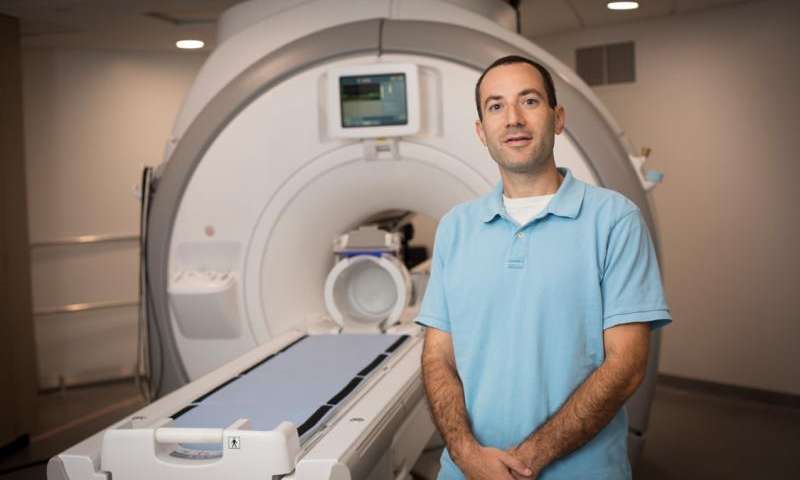
Real-time vocal tract MRI
Our lab is part of the Cornell Speech Imaging Group (SIG), a cross-disciplinary team of researchers using real-time magnetic resonance imaging to study the dynamics of speech articulation.
Articulatory movement tracking
We use the Northern Digital Inc. Wave motion-capture system to study speech articulatory patterns and motor control.

Sound Booth
Our isolated sound recording booth serves a range of purposes--from basic recording to perceptual, psycholinguistic, and ultrasonic experimentation.
We also have the necessary software and audio interfaces to perform low latency real-time auditory feedback experiments via MATLAB and Audapter.

©Copyright 2020, Cornell University